Baye Asmamaw

Python Connoisseur
Data Scientist
View My LinkedIn Profile
Data Science Portfolio
Here are some of my best Data Science Projects. I have explored various deep learing and machine-learning algorithms for different datasets. Feel free to contact me to learn more about my experience working with these projects.
Data Science and Machine Learning Capstone Project by IBM

Data: (1) data source API (2) data source web scraping
Skills used: python, API request, web scraping, numpy, pandas, matplotlib, seaborn, plotly, folium, sklearn
Project Objective: To predict if first launch of Falcon 9 rocket lands
Quantifiable result: The model predicted diseases with 83% accuracy various models.
- Used various techniques to clean the dataset and make it ready
- EDA was performed
- Logistic reggression, descision tree, KNN and SVM models with hyperparameter tuning by Grid Search CV
- 83% accuracy was found with all models
- models evalueted with confusion matrics, accuracy and fl-scores
- Explored result by providing all new test data that the model hasn’t seen before
Biodiesel Production Optimization
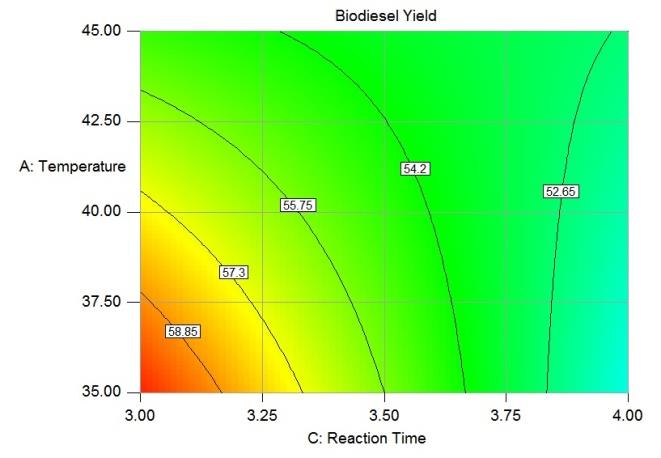
Data: Lab generated
Skills used: excel, ANOVA, matplotlib, seaborn, design expert
Project Objective: determine optimum biodiesel production conditions
Quantifiable result: Achieved an improved 59% reaction conversion rate and a 95% accuracy using polynomial regression degree 2.
- data was lab generated for train, test and validation data sets
- EDA was performed
- polynomial regression with degree 2 was used
- A 95% accuracy was fachieved
- Model was evalued using R squared, sum of errors

Data: data
Skills used: Python, Numpy, Matplotlib, Seaborn, Tensor flow, Neural Networking, Keras,
Project Objective: To predict the disease type
Quantifiable result: The model predicted diseases with 97% accuracy using CNN.
- Used various techniques to clean the dataset and make it ready
- EDA was performed
- A CNN model was bult
- A 97% accuracy was found using 30 epochs
- Model was evalued using accuracy
- Explored result by providing all new test data that the model hasn’t seen before
Amazon Fine Food Reviews Analysis (with SMOTE)

Data: data
Skills used: Python, Numpy, Matplotlib, Seaborn, ntlk, re, scikitplot, SKlearn
Project Objective: To review customer feedbacks
Quantifiable result: The model identified positive and negative reviews 96% accuracy using BoW model, 94% using TF-IDF model with Naive Bayes.
- Used various techniques to clean the dataset and make it ready
- EDA was performed
- SMOTE was performed
- BoW model was bult with Naive Baye’s classifier
- A 97% accuracy was found
- TF-IDF model was built with Naive Baye’s classifier
- A 94% accuracy was achieved
- Explored result by providing all new test data that the model hasn’t seen before

Data: data
Skills used: Python, Pandas, SKlearn, Matplotlib, Seaborn, Pycountry, Gradio
Project Objective: To find features correlated to increased suicide rates among different countries globally, across various socio-economic spectrum, and make predictions for the fututre
Quantifiable result: The number of suicide cases per year for each country using 99% accuracy using Random Forest Regressor.
- Used various techniques to clean the dataset and make it ready
- EDA was performed
- Linear Regression and Random Forest Resgression were applied
- A 99% accuracy was found using the Random Forest Regressor
- Model was evalued using accuracy, precision, recall, confusion matrix and classification report was compared
- Explored various ways to interprete the result
- Model deployment was performed using gradio
Employees-Attrition-Prediction

Skills used: Python,Numpy, Pandas, SKlearn, Matplotlib, Seaborn, Plotly express
Project Objective: Prediction of whether a given employee will leave in the next two quarters or not
Quantifiable result: The probablity of an employee leaving was predicted a accuracy of 80% using Naive Baye’s classifier.
- Data was cleaned using various techniques
- EDA was performed to better understand the dataset
- Categorical variables were encoded
- Scaling was performed
- Cleaned, encoded and scaled data was fitted to Naive Baye’s, Decison Tree, K Neighbors classifiers and Logistic Regression
- SMOTE was performed and data was re-fitted
- Model was evalued using accuracy, precision, recall, confusion matrix and classification report was compared Data: data

Skills used: Python,Numpy, Pandas, SKlearn, Matplotlib, Seaborn, Plotly express
Project Objective: Clustering of a dataset based on customers personality
Quantifiable result: Customers were clustered into four groups using K Means clustering.
- Data was cleaned using various techniques
- EDA was performed to better understand the dataset
- Categorical variables were encoded
- Outliers were taken care of
- Scaling was performed
- Cleaned, encoded and scaled data was fitted to K Means clustering
- Model was evaluated using Silhouttee Data data

Skills used: Python,Numpy, Pandas, SKlearn, Matplotlib, Seaborn, Plotly express
Project Objective: Prediction of happiness score for a given country
Quantifiable result: Happiness score was predicted with accuracy of 92% using Linear Regression.
- Data was cleaned using various techniques
- EDA was performed to better understand the dataset
- Categorical variables were encoded
- Outliers were taken care of
- Scaling was performed
- Cleaned, encoded and scaled data was fitted to Linear Regression
- Result was explored to see the effect of important features
- Model was evaluated with accuracy score, MSE, r2, and RMSE Data: [data]https://www.kaggle.com/unsdsn/world-happiness
Skills used: Python,Numpy, Pandas, SKlearn, Matplotlib, Seaborn, Plotly express
Project Objective: Heart disease were predicted for a given input
Quantifiable result: Overall prediction with accuracy of 59% using Decision Tree Classifier.
- Data was cleaned using various techniques
- EDA was performed to better understand the dataset
- Categorical variables were encoded
- Outliers were taken care of
- Scaling was performed
- Cleaned, encoded and scaled data was fitted to varios classifier models
- Result was explored to see the effect of important features
- Model was evaluated with accuracy, precision, recall, confusion matrix and classification report was compared
- Since the dataset has a very small set of data points and there were five outputs categories, the accuracy was low Data: data